Today i’ll gonna talk about queuing server and how you can you it to optimize processing you big data.
First i would like to start with defining the queuing process itself. queuing is putting jobs or processes in a queue and execute it when its ready for executing (depending upon its position in the queue). You may use for the jobs that takes long time processing (and may even fail).
I’ll explain it more deeply with an example of building a mail queue server.
You may do some processing before sending an email for user. generating statistics, pdfs or any other thing. example for emails that may take a long time processing is the weekly digest mail. And you can’t image how this could be a big load with a big data.
idea:
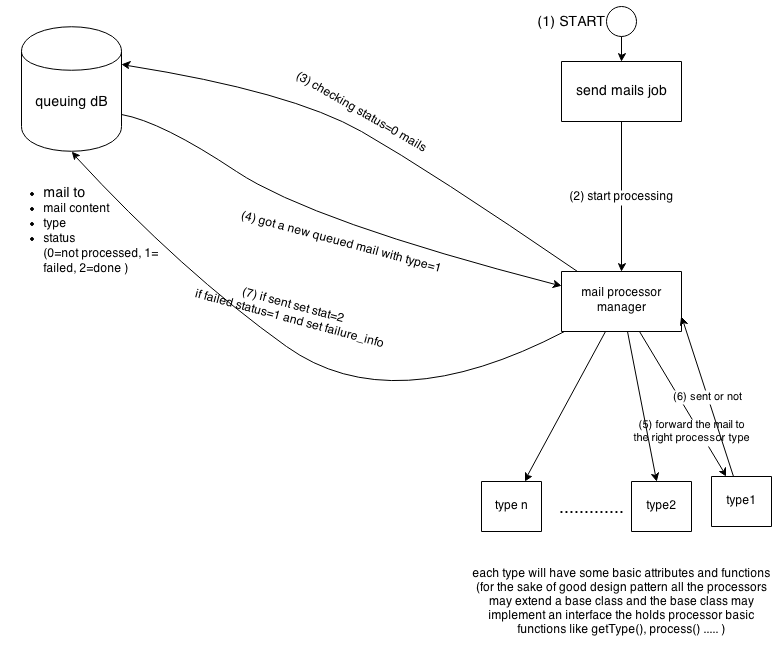
you may have a db table as a datastore for your mail queue. Table fields may be as following: “mail_to”, “mail_content”, “type”, “status”, “failure_info”. whenever you want to send a new mail just insert that table.
you start creating a command (job) that will keep track with the not sent mails (getting rows with status=0). After you get the mail you can start processing this mail (generating statistics, pdfs or whatever). Then try to send the mail. If it’s done set “status” to sent if not set the status to failed and update the “failure_info” attribute.
For the sake of good architecture of your code, you may use the processor design pattern to manage processing for each mail type.
here’s a simple link that can demonstrate the processor pattern http://www.openloop.com/softwareEngineering/patterns/designPattern/dPattern_CommandProcessor.htm
i’ve drew a simple chart that may simplify the whole idea.
Hope i’ve helped you with this blog. If you have any questions just drop me a comment or ding me if you have my social account or mail.
Thanks 🙂